| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
- Headless 컴포넌트
- JavaScript
- Custom Hook
- CS
- task queue
- Dockerfile
- Compound Component
- docker
- useEffect
- 명시적 타입 변환
- useMemo
- Event Loop
- 타입 단언
- Sparkplug
- 주니어개발자
- Render Queue
- Microtask Queue
- useCallback
- linux 배포판
- AJIT
- TypeScript
- 암묵적 타입 변환
- 프로세스
- prettier-plugin-tailwindcss
- 좋은 PR
- type assertion
- useLayoutEffect
- prettier
- React.memo
- react
- Today
- Total
구리
[JPA] JPA 기초 & 영속성 컨텍스트 본문
[JPA 소개]
관계형 DB를 사용할 땐 SQL에 의존적인 개발을 할 수 밖에 없고 객체 지향 & 관계형 DB의 패러다임 불일치와 같은 SQL 중심적인 개발의 문제점이 생깁니다. 하지만 현실적인 대안은 관계형 DB를 따라서 객체를 SQL로 변환 후 DB에 저장할 수 밖에 없기에 이런 과정들이 번거로웠습니다.
여기서 패러다임의 불일치란 ?
쉽게 말하면
객체 지향 프로그래밍은 필드, 메소드들을 묶어서 추상화,캡슐화해서 쓰는 게 목표 (추상화, 상속, 다형성 등의 개념)
관계형 데이터 베이스는 데이터를 정교화해서 보관 (객체지향에서 사용되는 개념이 존재하지 않음 그나마 상속과 비슷한 슈퍼타입-서브타입 관계)
그래서 탄생한 것이 JPA입니다.
ORM - '객체 관계 매핑'으로 객체는 객체대로, 관계형 DB는 관계형 DB대로 설계 후 중간에서 ORM 프레임워크가 매핑을 도와줌
JPA - Java persistence API로 자바 진영의 ORM 기술 표준
그러면 JPA를 사용해야 하는 이유는 무엇일까요 ?
- 신뢰할 수 있는 엔티티, 계층
- 생산성이 뛰어남 (CRUD, 특히 엔티티 조회후 객체의 필드값을 변경하면 알아서 DB에 반영됨)
- 유지보수가 뛰어남 (기존엔 필드 변경시 모든 SQL문을 수정해야 함, JPA는 알아서 처리)
- 객체와 관계형 DB 패러다임의 불일치를 해결
예시
class MemberService {
...
public void process() {
Member member = memberDAO.find(memberId);
member.getTeam(); //자유로운 객체 그래프 탐색
member.getOrder().getDelivery();
}
}원래는 memberDAO.find(); 호출시 위 메소드를 작업한 개발자가 해당 메소드를 어떻게 짰는지, DB에는 어떻게 구성이 되었는지 아무런 정보가 없기에 직접 까보기 전까진 member.getTeam() 와 같은 메소드를 쓸 수 있는 신뢰성이 없지만 JPA를 통해 데이터를 가져왔다면 자유로운 객체 그래프 탐색이 가능합니다.
(지연로딩이라는 기능으로 인해 해당 데이터를 신뢰할 수 있음)
(지연로딩 : 객체가 실제로 사용될 때 로딩! jpa에선 옵션 하나로 지연로딩 혹은 즉시 로딩으로 변경 가능)

[JPA 시작]
* 프로젝트 생성 (환경 설정)
- 자바 8이상
- 메이븐 설정
1. groupId: jpa-basic
2. artifactId: ex1-hello-jpa
3. version: 1.0.0
* 라이브러리 추가 (pom.xml)
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ex1-hello-jpa</artifactId>
<version>1.0.0</version>
<dependencies>
<!-- JPA 하이버네이트 -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>5.3.10.Final</version>
</dependency>
<!-- H2 데이터베이스 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<version>1.4.200</version>
</dependency>
</dependencies>
</project>
* JPA 설정 (resources > META-INF > persistemce.xml)
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.2"
xmlns="http://xmlns.jcp.org/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/persistence http://xmlns.jcp.org/xml/ns/persistence/persistence_2_2.xsd">
<persistence-unit name="hello">
<properties>
<!-- 필수 속성 -->
<property name="javax.persistence.jdbc.driver" value="org.h2.Driver"/>
<property name="javax.persistence.jdbc.user" value="sa"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.url" value="jdbc:h2:tcp://localhost/~/test"/>
<property name="hibernate.dialect" value="org.hibernate.dialect.H2Dialect"/>
<!-- 옵션 -->
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="hibernate.use_sql_comments" value="true"/>
<!--<property name="hibernate.hbm2ddl.auto" value="create" />-->
</properties>
</persistence-unit>
</persistence>참고로 javax.persistence로 시작하는 태그는 JPA 표준 속성이고 hibernate로 시작하는 태그는 하이버네이트 전용 속성입니다.
* 엔티티 생성, DB 테이블 생성
package hellojpa;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Member {
@Id
private Long id;
private String name;
public Member(){}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}create table Member (
id bigint not null,
name varchar(255),
primary key (id)
);
* 회원 엔티티 관련 간단한 실습
package hellojpa;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
public class JpaMain {
public static void main(String[] args){
EntityManagerFactory emf = Persistence.createEntityManagerFactory("hello");
EntityManager em = emf.createEntityManager();
EntityTransaction tx = em.getTransaction();
// 정석 코드
tx.begin();
try{
// 회원 등록
Member member = new Member();
member.setId(1L);
member.setName("helloA");
em.persist(member);
// 회원 수정 (수정 후 다시 DB에 저장하는 코드를 작성하지 않아도 DB에 수정사항 반영됨
Member findMember = em.find(Member.class, 1L);
findMember.setName("heloJPA");
tx.commit();
}catch (Exception e){
tx.rollback(); // 문제 생길 경우 rollback
}finally {
em.close(); // 사용 후 항상 자원해제
}
emf.close();
}
}※ 주의
EntityManagerFactory는 persistence.xml 파일에서 persistence-unit에서 설정한 이름으로 애플리케이션에서 1개만 생성하여 공유하여 사용해야 합니다.
Entitymanager는 DB 작업을 할 때마다 생성해서 사용해야 합니다. (쓰레드간 공유 X, 사용 후 버리기)
JPA 모든 데이터 변경은 트랜잭션 안에서 실행해야 합니다.
여기서 트랜잭션이란 ?
insert,update 등 작업 단위 라고 생각하면 됩니다.
[영속성 컨텍스트]
엔티티를 영구 저장하는 환경으로 공간의 의미로 엔티티 매니저를 생성하면 아래와 같이 영속성 컨텍스트가 1:1로 생성됩니다.
즉, Entitymanager.persist()는 db에 저장하는게 아니라 영속성 컨텍스트를 통해서 엔티티를 영속화합니다.
(= 엔티티를 영속성 컨텍스트에 저장한다는 의미)

그러면 데이터는 어느 시점에 DB에 저장될까요 ?
바로 트랜잭션 커밋하는 시점에 데이터를 저장하는 쿼리가 DB에서 실행됩니다.
[영속성 컨텍스트의 이점]
- 1차 캐시
- 동일성 보장
- 트랜잭션을 지원하는 쓰기 지연
- 변경 감지
* 1차 캐시
영속성 컨텍스트 내부에는 1차 캐시라는 것이 존재합니다.
즉, 어플리케이션과 DB 사이에 하나의 계층 (영속성 컨텍스트)가 존재하며 EntityManager.persist(객체); 실행시 영속 컨텍스트의 1차 캐시에 엔티티가 저장된다고 생각하면 됩니다. (DB에는 데이터가 아직 저장되지 않은 상태)
예시 - 1차 캐시 생성

// 엔티티를 생성한 상태(비영속)
Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
// 엔티티를 영속
em.persist(member);
또한 EntityManager.find() 실행시 jpa는 1차적으로 DB가 아닌 영속 컨텍스트의 1차 캐시를 탐색하게 됩니다.
1차 캐시 내에 일치하는 데이터가 없다면 DB에서 조회 후 1차 캐시에 데이터를 저장하게 됩니다.
예시 - 1차 컨텍스트 조회

Member member = new Member();
member.setId("member1");
member.setUsername("회원1");
//1차 캐시에 저장됨
em.persist(member);
//1차 캐시에서 조회
Member findMember = em.find(Member.class, "member1");
예시 - DB에서 데이터 조회

Member findMember2 = em.find(Member.class, "member2");
* 영속 엔티티의 동일성 보장
같은 트랜잭션 내에서 실행할 때 1차 캐시 덕분에 동일성이 보장됩니다.
(1차 캐시로 반복 가능한 읽기(REPEATABLE READ) 등급의 트랜잭션 격리 수준을 데이터베이스가 아닌 애플리케이션 차원에서 제공)
예시
Member a = em.find(Member.class, "member1");
Member b = em.find(Member.class, "member1");
System.out.println(a == b); //동일성 비교 true
* 엔티티 등록 (트랜잭션을 지원하는 쓰기 지연)
tx.commit() 을 실행하는 시점에 쓰기 지연 SQL 저장소에 있던 애들이 flush되면서 (DB에 sql문이 날아가는) DB에 데이터가 저장됩니다.
예시
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction();
//엔티티 매니저는 데이터 변경시 트랜잭션을 시작해야 한다.
transaction.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.
//커밋하는 순간 데이터베이스에 INSERT SQL을 보낸다.
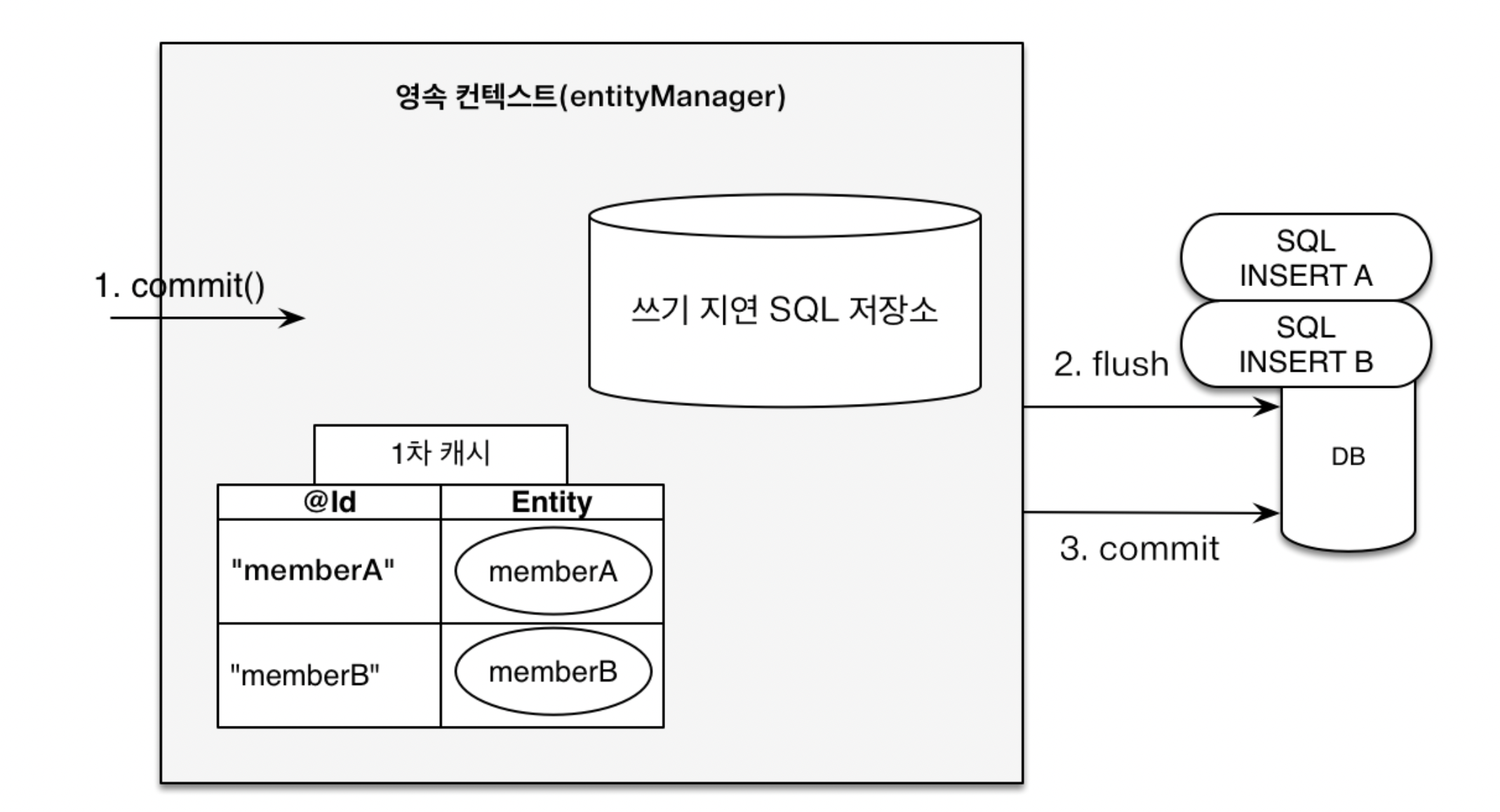
transaction.commit(); // [트랜잭션] 커밋다음과 같은 코드가 있다고 가정할때 각 코드당 실행되는 과정은 아래의 그림과 같습니다.
1. em.persist(memberA);
memberA라는 데이터를 저장할 insert 쿼리문을 DB에서 바로 실행하지 않고 일단 영속 컨텍스트의 쓰기 지연 SQL 저장소에 쌓아두며
1차 캐시에 memberA 엔티티를 저장합니다.

2. em.persist(memberB);
memberA와 마찬가지로 쓰기 지연 저장소에 insert memberB 쿼리문을 쌓아두고 1차 캐시에 memberB 엔티티를 저장합니다.

3. trasaction.commit();
트랜잭션 커밋 시점에 영속 컨텍스트의 쓰기 지연 SQL 저장소에 있던 쿼리문을 DB에 보내 데이터를 저장합니다.
*엔티티 수정 - 변경 감지 (Dirty Checking)
DB에서 데이터를 가져와 수정 후 따로 em.update()같이 따로 저장하지 않아도 트랜잭션 커밋 시점에 JPA가 알아서 update 쿼리문을 실행합니다.
JPA는 엔티티 & 스냅샷을 비교 후 스냅샷과 엔티티 데이터에 변화가 있다면 쓰기 지연 SQL 저장소에 update 쿼리문을 저장 후 트랜잭션 커밋 시점에 update 쿼리문을 DB에게 날립니다.
( 스냅샷 : 1차 캐시에는 값을 최초로 가져온 시점에 그 데이터 상태를 스냅샷으로 만들어 놓습니다.)
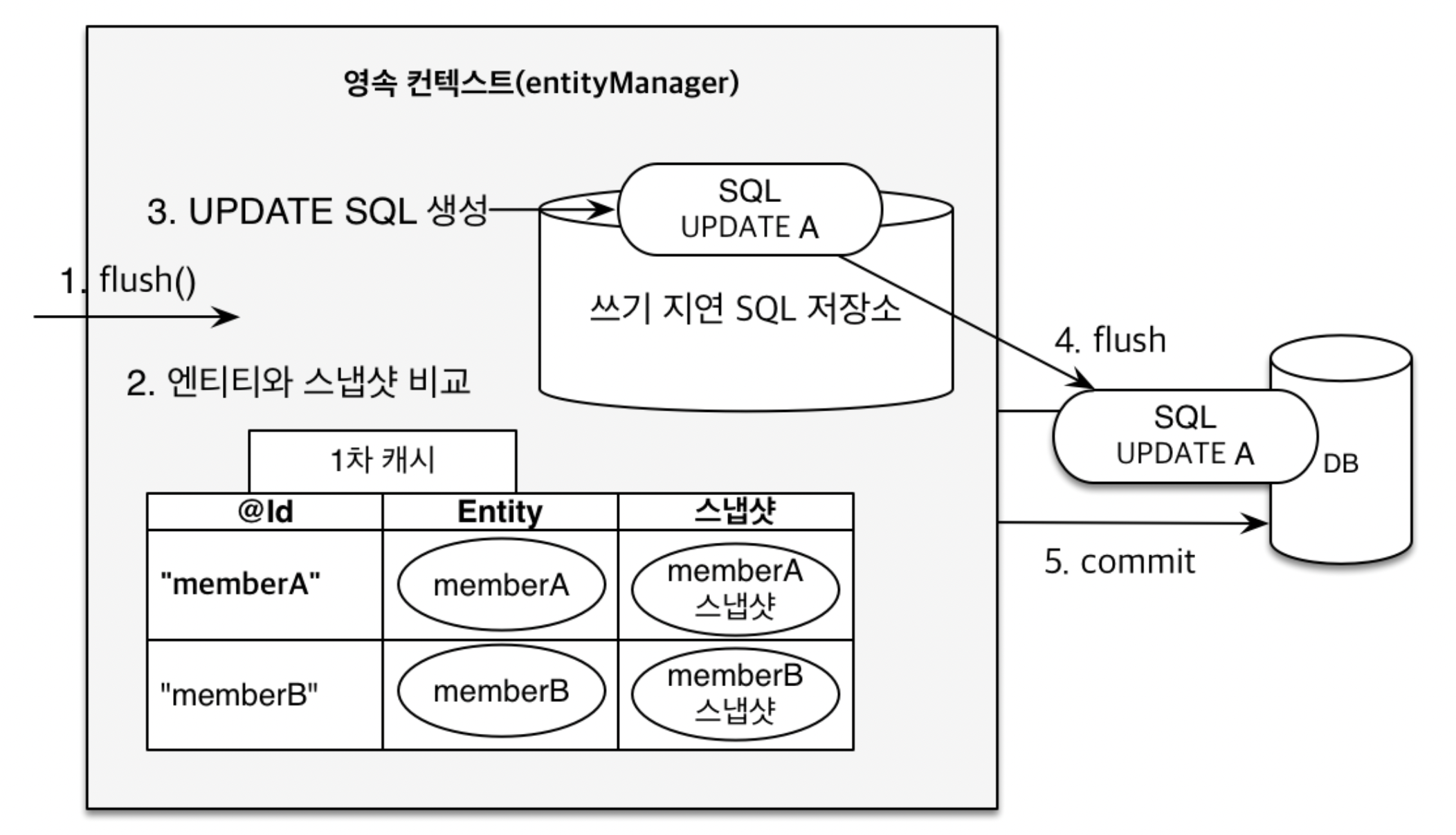
[플러시란?]
영속성 컨텍스트의 변경 내용을 DB에 반영하는 것을 의미하며 플러시가 발생하면 다음과 같은 과정이 진행됩니다.
- 변경 감지 (Dirty Checking)
- 수정된 엔티티 쓰기 지연 SQL 저장소에 등록
- 쓰기 지연 SQL 저장소의 쿼리를 DB에 전송 (등록,수정,삭제 쿼리)
참고로 플러시는 영속성 컨텍스트를 비우지 않으며 영속성 컨텍스트의 변경 내용을 DB에 동기화하는 과정이라고 생각하면 됩니다.
또한 트랜잭션이라는 작업 단위가 중요한데 그 이유는 커밋 직전에만 동기화하면 되기 때문입니다.
그러면 영속성 컨텍스트를 플러시하는 방법은 무엇일까요 ?
- em.flush() : 강제적으로 직접 호출
- 트랜잭션 커밋 : 플러시 자동 호출
- JPQL 쿼리 실행 : 플러시 자동 호출
따라서 플러시를 직접 호출할 경우는 많지 않습니다.
출처 : 김영한 - 자바 ORM 표준 JPA 프로그래밍
'JPA' 카테고리의 다른 글
| [JPA] 다양한 연관관계 매핑 (0) | 2021.09.02 |
|---|---|
| [JPA] 연관관계 매핑 (0) | 2021.09.01 |

