| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 좋은 PR
- jotai
- docker
- TypeScript
- 프로세스
- 25년 2월
- linux 배포판
- Custom Hook
- 암묵적 타입 변환
- zustand
- Headless 컴포넌트
- react
- AJIT
- Render Queue
- 회고
- prettier-plugin-tailwindcss
- CS
- Microtask Queue
- Compound Component
- type assertion
- helm-chart
- JavaScript
- Sparkplug
- msw
- Recoil
- useLayoutEffect
- 타입 단언
- 명시적 타입 변환
- mocking
- 클라이언트 상태 관리 라이브러리
- Today
- Total
구리
React 동작원리(Virtual DOM과 Fiber) 본문
React 동작원리에 대해 공부한 것을 정리한 글입니다. 피드백은 언제나 환영입니다!
서론
프론트엔드 역사 (React를 곁들인)
2000년대까지는 LAMP 스택(Linux, Apache 웹서버, MySQL, PHP)이 강세였으며 웹 서버에서 HTML 페이지를 만들어 클라이언트에게 제공하는 방식으로 브라우저는 단순히 HTML 페이지 렌더링, JS는 폼 처리와 같은 부수적인 역할만 하는 방식으로 프론트엔드는 수동적인 역할이었다.
2010년대부터는 웹소켓, 캔버스, 지오로케이션 같은 다양한 기능을 브라우저에서 제공하며 JS의 역할은 더욱 넓어졌다. 그러나 DOM API를 다루는 것은 까다로웠기에 JS 코드가 복잡해지게 되었다.
간단한 예시로 DOM을 선택하는 방법에 대해 살펴보면 다음과 같다.
ID 선택자를 활용하는 getElementById와 Class 선택자를 활용한 getElementByClassName이 있다.
둘 다 DOM을 가져오는 함수지만 서로 다른 타입의 값을 리턴한다.
const container = document.getElementById('container');
console.log(container); return <div id="container"></div>
console.log(container.__proto__); return HTMLDivElement {Symbol: 'HTMLDivElement'}
console.log(container.__proto__.__proto__); return HTMLElement
console.log(container.__proto__.__proto__.__proto__); return Element
const container = document.getElementsByClassName('container');
console.log(container); return HTMLCollection [className: 'container']
console.log(container.__proto__); return HTMLCollection {Symbol: 'HTMLCollection'}
console.log(container.__proto__.__proto__); return {constructor: Object()}
console.log(container.__proto__.__proto__.__proto__); return null또한 브라우저별로 DOM API와 스펙이 각각 달랐기에 위와 같은 사항들을 고려해 웹 개발을 해야 한다면 그 복잡성으로 인해 신경 써야 할 것들이 굉장히 많아지게 된다.
jQuery는 DOM Selector API로 DOM을 선택해 특정 이벤트 발생시 변화를 주는 방식으로 매우 쉽고 직관적이다. 따라서 jQuery는 인기를 얻게 되었지만 속도가 매우 느리다는 단점도 존재했다.
이유는 여러 코드로 wrapping되어 있어, 실제 태그를 추가하기까지 상당히 많은 과정을 거치기 때문이다. 크로스 브라우징 등의 이슈를 해결하기 위해 기존 네이티브 코드르 수없이 많은 코드들로 wrapping해서 제공해주다보니 이런 단점들이 존재했다.
또한 다룰 데이터가 많아질수록 더 많은 DOM을 선택해야 했기에, 페이지가 복잡해질수록 코드가 기하급수적으로 늘어나 코드 관리가 힘들어지고 유지 보수도 어렵게 된다.
결론적으로 jQuery는 과거에는 DOM API를 손쉽게 다룰 수 있는 괜찮은 라이브러리였지만 현재는 느리며, 개발 생산성에도 좋지 않다.
React가 인기 있어진 이유
React는 상태만 변경하면 상태를 기준으로 DOM API를 알아서 처리하며 DOM을 렌더링한다. 상태를 React의 선언적인 문법으로 관리해주면, 나머지는 React가 알아서 처리해주는 방식으로 DOM API를 효과적으로 다룰 수 있다.
상태(state)란 ? 상호 작용의 결과로 지속적으로 변경될 수 있는 값으로 form 입력 필드, toggle 상태 등을 의미한다.
그렇다면 React는 어떤 방식으로 state가 변경된 것을 감지하고 어떻게 효과적으로 DOM API를 다루는 것일까?
답을 찾기 위해 React의 동작 원리에 대해 살펴본다.
본론
React 동작 원리
일반적으로 브라우저는 Critical Rendering Path(CRP) 과정을 거쳐 웹페이지를 그려주게 된다. (자세한 건 작성한 브라우저 렌더링 과정 글을 참고하면 된다.)
만약 사용자의 상호 작용이 발생해 요소의 색상을 변경한다면 repaint, 요소의 위치나 크기를 변경한다면 reflow 과정이 일어나게 된다. 여기서 요소가 많은 자식 요소를 가지고 있다면 하위 자식 요소도 변경돼야 하기에 더 많은 비용을 브라우저와 사용자가 지불하게 된다.
개발자의 관점에서 보면 하나의 인터렉션으로 인해 페이지 내부의 DOM의 모든 변경 사항을 추적하는 것은 굉장히 번거로운 일이다. 그리고 대부분의 경우, 인터렉션에 모든 DOM의 변경보다는 결과적으로 만들어진 DOM 결과물만 알고 싶을 것이다.
이런 문제를 해결하기 위해 등장한 것이 바로 Virtual DOM(가상 DOM)으로 다음과 같은 방식으로 동작한다.
1. 실제 DOM으로부터 Virtual DOM을 만든다. (메모리 상에 존재하는 가상의 DOM 객체)
2. 상태 변경을 감지해 새로운 버전의 Virtual DOM을 만든다.
3. Old Virtual DOM과 New Virtual DOM을 비교한다.
4. 비교 과정을 통해 발견한 차이점을 Real DOM에 한꺼번에 적용한다.
따라서 여러 번 발생했을 렌더링 과정을 최소화할 수 있고 브라우저, 개발자의 부담을 덜 수 있다.
(여러 번의 업데이트를 한꺼번에 묶어서 처리한다는 의미는 한번 렌더링 되는 과정에서 여러 곳이 바뀌는 경우, 업데이트를 모아 한꺼번에 Real DOM에 적용해 한번만 리렌더링 하게끔 한다는 것을 의미)
또한 비교적 용량이 큰 Real DOM 과 업데이트된 Real DOM을 비교하여 변경된 부분을 적용시키는 것이 아닌, 비교적 용량이 작은 객체인 Virtual Dom과 업데이트된 Virtual Dom을 비교하기에 비용도 적게 든다는 장점이 있다.
Virtual DOM이 Real DOM을 관리하는 방식보다 더 빠를까?
React에서도 최종적으로 실제 DOM에 변경사항을 반영할 때는 appendChild와 같은 DOM API를 사용하게 된다. (소스 코드 참고)
그렇다면 Real DOM을 이용해 변경사항을 모아서 한꺼번에 업데이트하는 것과 동일한 것 아닐까?
물론 DOM Fragment을 이용하면 가능하지만 위에서도 말했듯이 개발자가 DOM 변경사항을 추적하고 모아서 수동으로 한꺼번에 Real DOM에 반영하는 것은 굉장히 번거로운 일이다.
React는 비교적 가벼운 Virtual DOM 객체을 이용해 변경사항을 모아서 한꺼번에 Real DOM에 업데이트한다는 점에서 다음과 같은 장점을 가진다고 할 수 있다.
- Real DOM 조작 횟수를 줄여 불필요한 리렌더링 과정 최소화 및 리소스 소모 감소
- 메모리상 가벼운 객체를 조작하기에 무거운 Real DOM을 다루는 것보다 비용 감소
- Virtual DOM을 이용해 DOM 관리 작업을 추상화, 자동화시켜주기에 생산성 증가
[참고 자료]
- https://velopert.com/3236
- https://stackoverflow.com/questions/61245695/how-exactly-is-reacts-virtual-dom-faster
React는 Virtual DOM을 어떻게 처리할까?
React는 변경을 감지하면 변경된 부분을 모아서 실제 DOM에 반영하는데 이 과정을 Reconciliation(재조정)이라고 한다. React 16 이전에는 Stack 구조를 사용한 재조정 방식(Stack Reconciliation)을 사용했는데 어떤 한계점으로 인해 React 16부터 Fiber Reconciliation을 사용하게 되었다. 어떤 문제점이 있었고 Fiber Reconciliation는 문제를 어떻게 해결하는 걸까?
Stack Reconciliation의 한계점
크게는 Tree 구조와 JavaScript의 CallStack을 사용하는 것에 대한 한계점이 있었다.
Virtual DOM은 일반적인 Tree 구조로 이뤄져 있는데 2개의 Tree를 비교하려면 재귀적인 알고리즘을 사용해야 한다. 재귀 알고리즘은 중간에 멈추거나 다시 시작할 수 없기에 JavaScript의 Call Stack 위에서 동작하는 Stack Reconciliation 작업이 길어진다면 유저의 클릭 이벤트나 브라우저의 화면 렌더링이 동작하지 않을 수도 있다. 따라서 이와 같은 문제를 해결하기 위해 React Fiber Architecture를 도입했다.
React Fiber Architecture의 목표
React Fiber는 재귀적으로 이뤄지는 순회 작업을 멈출 수도 있고, 재개할 수도 있고, 우선순위에 따라 스케줄링할 수 있는 Reconciliation을 만들기 위해 아래 4가지 목표를 설정했다.
1. 작업을 중단하고 이후에 다시 시작할 수 있어야 한다.
2. 다른 종류의 작업에 우선 순위를 부여할 수 있어야 한다.
3. 이전에 완료한 작업을 다시 사용할 수 있어야 한다.
4. 필요 없어진 작업은 중단할 수 있어야 한다.
위 4가지 목표를 달성하게 된다면 작업 자체가 길더라도 멈췄다가 재개하여 다른 이벤트가 실행되도록 유연하게 동작할 수 있고, 이전 작업을 재사용해 불필요한 작업을 방지할 수 있다.
React Fiber는 어떻게 스케줄링을 구현했을까?
React는 단일 연결 리스트 형태로 구현된 Fiber를 통해 순회를 멈추고 Call Stack에 쌓인 함수의 크기를 줄일 수 있었다.
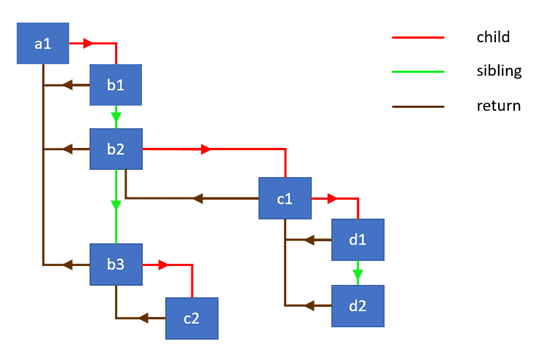
render 함수의 인자로 넘어온 element 객체는 fiber node로 변환되고 그 node들은 모두 연결되는데 예시 코드로 같이 살펴본다.
class Node {
constructor(instance) {
this.instance = instance;
this.child = null; // 첫번째 자식에 대한 참조
this.sibling = null; // 첫번째 형재에 대한 참조
this.return = null; // 부모에 대한 참조
}
}그리고 인자로 받아온 노드들을 모두 단일 열결 리스트로 연결시켜주는 함수가 있다.
function link(parent, elements) {
if (elements == null) elements = [];
parent.child = elements.reduceRight((previous, current) => {
const node = new Node(current);
node.return = parent;
node.sibling = previous;
return node;
}, null);
return parent.child;
}그리고 이 link 함수는 parent 노드의 가장 첫번째 자식을 반환한다.
const children = [{name: 'b1'}, {name: 'b2'}];
const parent = new Node({name: 'a1'});
const child = link(parent, children);
console.log(child.sibling.name === 'b1'); // true
console.log(child.sibling.instance === children[1]); // true또한 현재 노드와 자식 노도들을 연결을 도와주고 노드에 대핸 작업을 수행하는 helper 함수가 있다.
function doWork(node) {
console.log(node.instance.name);
const children = node.instance.render();
return link(node, children);
}마지막으로 부모 node를 처음으로 깊이 우선 탐색을 진행하게 된다.
여기서 깊이 우선 탐색이란 먼저 아래 방향으로 child를 활성화 노드로 지정하면서 doWork()로 계속 child를 연결 리스트로 연결 후 child가 없으면 그때 sibling을 활성화 노드로 지정한다.
다시 doWork()로 계속 child를 연결 리스트로 연결하다가 더이상 sibling이 없다면 부모로 올라가면서 위 사진에 있는 구조로 완성된다. (코드 예시)
function walk(o) {
let root = o;
let current = o;
while (true) {
let child = doWork(current);
// 자식이 있다면 현재 active node로 지정
if (child) {
current = child;
continue;
}
// 가장 상위 노드까지 올라갔다면 함수 종료
if (current === root) {
return;
}
// 형제 노드를 찾을 때까지 while문 진행, 자식 -> 부모로 올라가면서 형제가 있는지 찾아주는 로직
while (!current.sibling) {
if (!current.return || current.return === root) {
return;
}
current = current.return;
}
// sibling을 발견하면 sibling을 현재 active node로 지정
current = current.sibling;
}
}보다시피 위 함수를 실행하면 계속해서 Stack이 쌓이지 않는다. Call Stack의 가장 아래에는 walk 함수가 있고, 계속해서 doWork 함수가 호출되었다가 사라지게 되기 때문이다.
이 함수의 핵심은 current node에 대한 참조를 유지하고 있다는 점이다. 따라서 함수가 중간에 멈춰도 current node로 돌아와서 작업을 재개할 수 있다. 이런 구조를 통해 재귀적 순회가 가진 문제를 해결할 수 있다.

지금까지 어떻게 중간에 하던 작업을 멈췄다 재개할 수 있는지 알아봤다. 그렇다면 이 작업을 언제 실행하고 언제 멈추는 걸까?
[참고 자료]
https://github.com/acdlite/react-fiber-architecture
requestIdleCallback과 Fiber
하나의 프레임 안에서는 아래와 같은 일들이 실행된다.
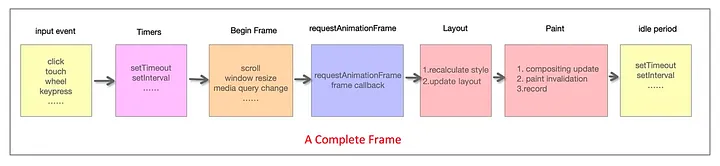
- 입력 이벤트를 처리해 최대한 빨리 사용자에게 피드백을 제공
- 타이머가 예정된 시간에 도달했는지 확인하고 해당 callback을 동시에 수행
- window.resize, scroll, media query 변경 등을 포함한 Begin Frame(각 프레임의 이벤트)을 확인한다.
- request AnimationFrame(rAF)을 실행한다. 페인팅 전에 rAF callback을 실행한다.
- 레이아웃 계산 및 업데이트를 포함한 레이아웃 작업, 즉 요소가 페이지에 스타일되고 표시되는 방법을 수행한다.
- Paint 작업을 수행한다. 트리 내 node의 크기와 위치를 구하고, 각 요소의 내용을 browser에서 계산한다.
- 브라우저가 유휴시간에 들어간다.
16ms라는 하나의 프레임 안에서 main task가 진행되고 남은 시간(idle period)인 7번의 순간에 특정 함수가 실행될 수 있도록 하는 API가 있는데 바로 requestIdleCallback이다.
React Fiber는 requestIdleCallback을 활용하게 된다. Fiber는 주어진 nodes를 잘게 쪼개고 각각의 fiber node를 하나의 실행 단위(unit of work)로 여긴다. 이렇게 잘게 쪼갠 작업들을 idle period에 하나하나씩 실행시킨다. 그래서 하나를 실행할 때마다 브라우저에게 남는 시간이 더 있다면 fiber에 올라간 작업이, 시간이 없다면 browser task가 실행된다.
결론적으로 하나의 프레임 단위에 하나의 fiber node가 올라가면서 실행과 중단을 browser task에 맞게 반복하는 것으로 이런 흐름은 아래 그림과 같이 표현된다.
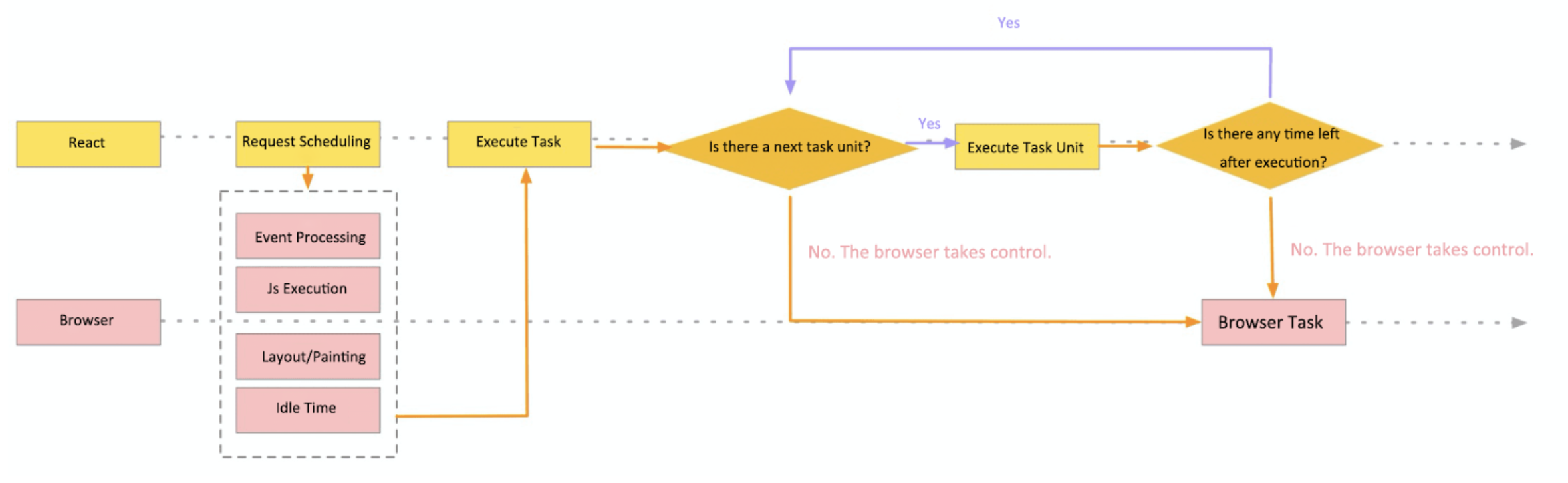
[참고 자료]
https://medium.com/imgcook/a-closer-look-at-react-fiber-b2ab072fcc2a
Fiber Reconciliation의 동작 방식
마지막으로 Fiber Reconciliation의 과정에 대해 알아보겠다. 해당 과정은 2개의 Phase로 Render 그리고 Commit Phase가 있다.
Render Phase
Render Phase는 Virtual DOM을 조작하는 모든 일련의 과정으로,해당 단계가 끝나면 재조정이 완료된 Virtual DOM을 얻게 된다. 또한 실제 DOM에 마운트해야하는 내용들을 모아둔 effect list도 생성된다. 예를 들어 생성, 삭제, 속성 수정 등이 존재한다. 해당 Phase는 중간에 멈추고 다시 시작할 수 있다.
Commit Phase
Render Phase에서 산출된 effect list를 토대로 실제 DOM에 반영을 진행한다. 이 과정은 중간에 멈출 수 없으며 동기적으로 한번에 진행되게 된다. 이 과정으로 실제 DOM 반영을 완료해 단계가 종료되며 Call Stack 점유가 끝나면, 브라우저가 UI에 반영하게 된다.
[참고 자료]
https://wikibook.co.kr/react-deep-dive/
결론
위 글은 아래와 같이 요약할 수 있을 것 같다.
React는 Virtual DOM을 사용해 아래와 같은 장점을 제공한다.
- DOM의 변경점을 모아 한꺼번에 RealDOM에 적용함으로써 Real DOM 조작 횟수를 줄여 불필요한 리렌더링 과정을 최소화하고 리소스 소모가 감소된다.
- 메모리상 가벼운 객체를 조작하기에 무거운 Real DOM을 다루는 것보다 비용이 감소된다.
- Virtual DOM을 이용해 DOM 관리 작업을 추상화, 자동화시켜주기에 개발 생산성이 증가된다.
React는 Fiber Architecture를 도입해 아래와 같은 장점을 제공한다.
- 기존의 재귀적인 Virtual DOM 비교 방식으로 인한 Call Stack 점유 및 작업 중단, 재개의 불가한 문제를 해결한다.
- Fiber Architecture는 단일 연결 리스트로 구현된 Fiber를 이용해 최신 노드에 대한 참조를 유지하기에 작업 중단 후 작업 재개가 가능하다.
- 브라우저의 유휴 시간에 작업을 진행하는
requestIdleCallback함수를 이용해 각각의 Fiber node 작업 단위를 실행함으로써 하나의 프레임 단위에 실행과 중단을 browser task에 맞게 반복하는 방식으로 진행한다.
'React' 카테고리의 다른 글
| [React] React Hook 파헤쳐보기 - useCallback, useMemo (React.memo를 곁들인) (2) | 2024.11.16 |
|---|---|
| [React] React Hook 파헤쳐보기 - useEffect (2) | 2024.11.08 |
| [React] React Hook 파헤쳐보기 - useState (0) | 2024.10.21 |
| [React] 변경에 유연한 Headless 컴포넌트 만들기 (0) | 2024.01.16 |
| [Webpack] 모듈 번들러, 그리고 ESBuild를 통한 빌드 속도 개선 (1) (0) | 2023.09.21 |



