| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Microtask Queue
- 프로세스
- 타입 단언
- docker
- 좋은 PR
- CS
- Headless 컴포넌트
- Sparkplug
- AJIT
- Custom Hook
- jotai
- 암묵적 타입 변환
- Recoil
- 클라이언트 상태 관리 라이브러리
- type assertion
- msw
- zustand
- JavaScript
- react
- Compound Component
- prettier-plugin-tailwindcss
- Render Queue
- TypeScript
- mocking
- 25년 2월
- 명시적 타입 변환
- helm-chart
- useLayoutEffect
- 회고
- linux 배포판
- Today
- Total
구리
Redux Toolkit은 언제 사용해야 할까? 본문
React 상태 관리 라이브러리에 대해 공부하며 정리한 글입니다. 피드백은 언제나 환영입니다!
Redux가 나온 이유
Redux는 JS 상태관리 라이브러리로 전역 상태 관리시 Redux를 쉽게 사용할 수 있는 Redux Toolkit을 많이 사용한다. 그렇다면 Redux 탄생 이전에는 클라이언트 상태 관리를 어떻게 했을까?
전역 상태 관리를 생각하면 React가 제공하는 Context API를 떠올릴 수 있지만 이는 16.3 버전으로 2018년에 출시되었다. (엄밀히 말하면 상태 관리보다는 상태 주입을 도와주는 역할이다.) 그 전까지는, React에서 대표적인 상태 관리 라이브러리는 없었다.
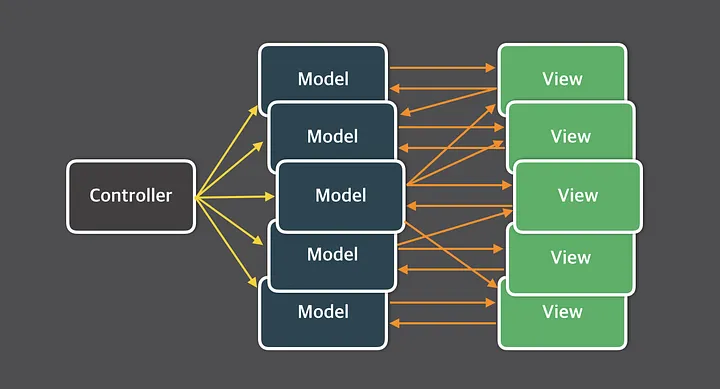
기존에는 MVC 패턴을 주로 사용했는데 애플리케이션이 비대해지며 상태(데이터)도 많아짐에 따라 상태 변화를 추적하고 이해하기 어려운 상황이었다.
그러다 2014년경, Flux 패턴을 기반으로한 Flux 라이브러리가 탄생하게 된다. 양방향 데이터 바인딩으로 인해 변경 시나리오가 복잡해져 상태 변화를 추적 및 관리하기 어렵다고 판단한 페이스북 팀은 양방향이 아닌 단방향으로 데이터를 관리하는 Flux 패턴의 라이브러리를 만들게 된 것이다.
아래 사진은 Flux의 패턴으로 Action이 발생하면, Dispatcher에서 이를 받와서 해석한 후 Store에 저장된 정보를 변경하여 그 결과가 View로 다시 전달되는 과정이 반복되며 단방향으로만 데이터가 관리되는 것을 볼 수 있다.
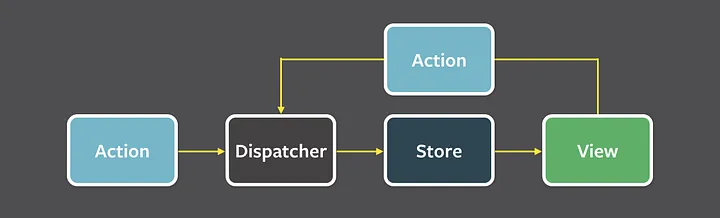
단방향 데이터 흐름 방식을 적용하게 되면 사용자의 액션에 따라 데이터를 갱신하고 어떻게 업데이트 할지 코드로 작성해야 하기에 코드의 양이 많아지며 개발자가 수고로워진다. 그러나 데이터의 흐름은 모두 한 방향이기에 데이터 흐름을 추적하기 쉽고 코드를 더 쉽게 이해할 수 있다.
React도 대표적인 단방향 데이터 바인딩 기반의 라이브러리였기에 Flux 패턴과 궁합이 잘 맞았으며 Flux 패턴을 따르는 다양한 라이브러리들이 많이 나왔었다.
그때 등장한 것이 Redux로 물론 Flux로부터 영감을 받은 라이브러리였지만 특이한 점은 Elm 아키텍처를 도입했다는 것이다. Elm은 웹페이지를 선언적으로 작성하기 위한 언어로 다음 예제를 가볍게 살펴본다.
import Browser
import Html exposing (Html, button, div, text)
import Html.Events exposing (onClick)
main =
Browser.sandbox { init = 0, update = update, view = view }
type Msg = Increment | Decrement
update msg model =
case msg of
Increment ->
model + 1
Decrement ->
model - 1
view model =
div []
[ button [ onClick Decrement ] [ text "-" ]
, div [] [ text (String.fromInt model) ]
, button [ onClick Increment ] [ text "+" ]
]위 코드처럼 Elm은 크게 3가지 개념을 사용하고 있다.
- model : 애플리케이션의 상태
- view : 모델을 표현하는 HTML
- update : 모델을 수정하는 방식
Elm은 Flux와 비슷하게 데이터 흐름을 3가지로 분류 후 이를 단방향으로 강제하고 있다.
Redux는 다른 Flux 구현체에서 흔히 볼 수 있는 다중 저장소와 달리 Elm 아키텍처에서 부분적으로 영감을 받은 단일 저장소를 사용한다.
이제부터는 Redux 핵심 개념을 보면서 어떤 이점을 제공하는지 자세히 알아본다.
[참고 자료]
https://frontendmastery.com/posts/the-new-wave-of-react-state-management/
Redux 핵심 개념
아래는 redux의 핵심 개념을 알기 위해 알아야 할 용어들이다.
- Store : 실제 데이터가 저장되는 전역 저장소
- Reducer : 특정 action에 따라 store 값을 변경
- Action : reducer가 어떤 동작을 수행해야 할지 알려주는 역할
- Dispatcher : action을 호출할 때 사용하는 방식으로 컴포넌트에서 사용된다.
import { createStore } from 'redux';
// reducer
function counter(state = 0, action) {
switch (action.type) {
case 'INCREMENT':
return state + 1;
case 'DECREMENT':
return state - 1;
default:
return state;
}
}
let store = createStore(counter);
store.subscribe(() => console.log(store.getState()));
store.dispatch({type:'INCREMENT'});
// 출력: 1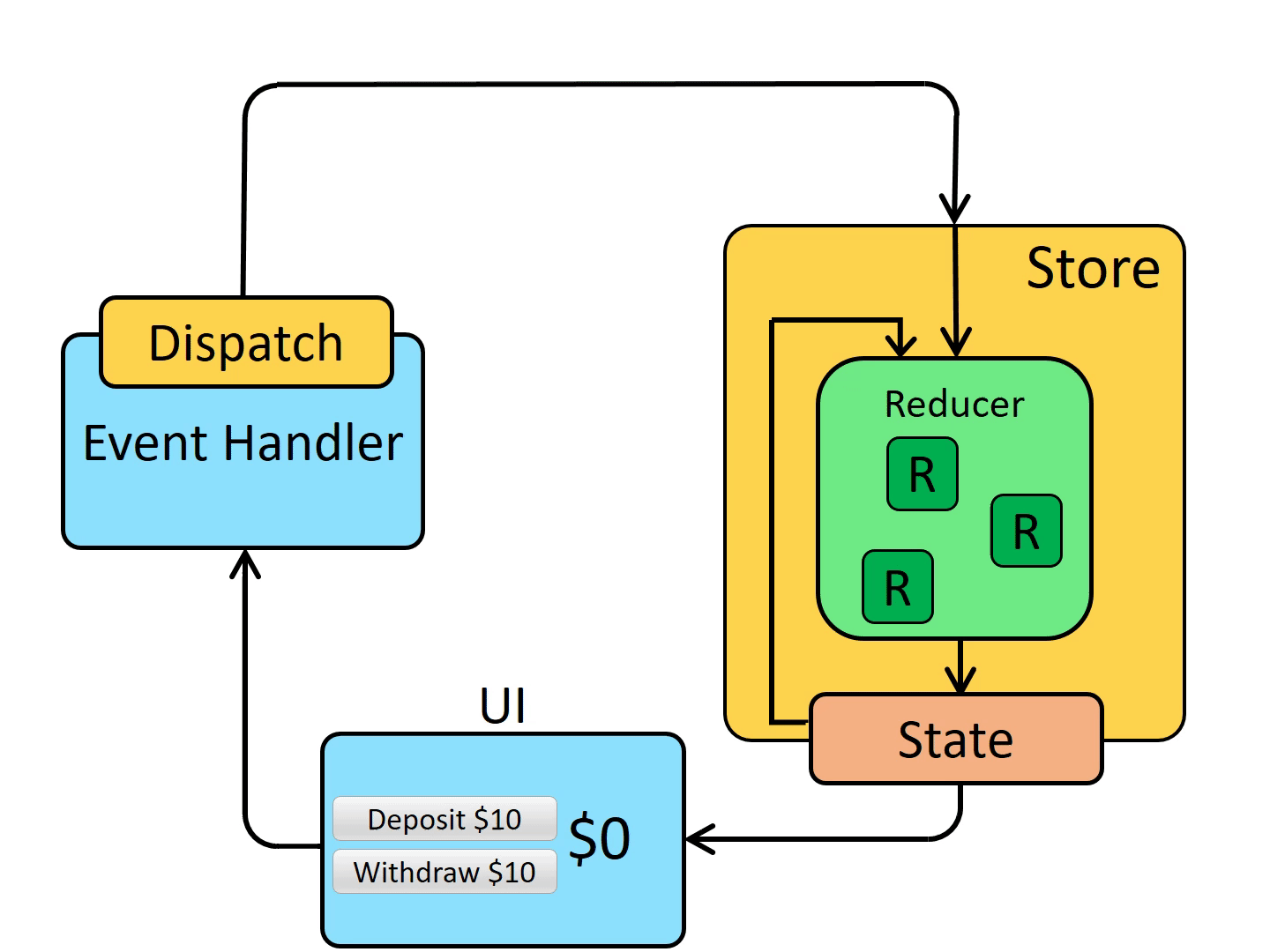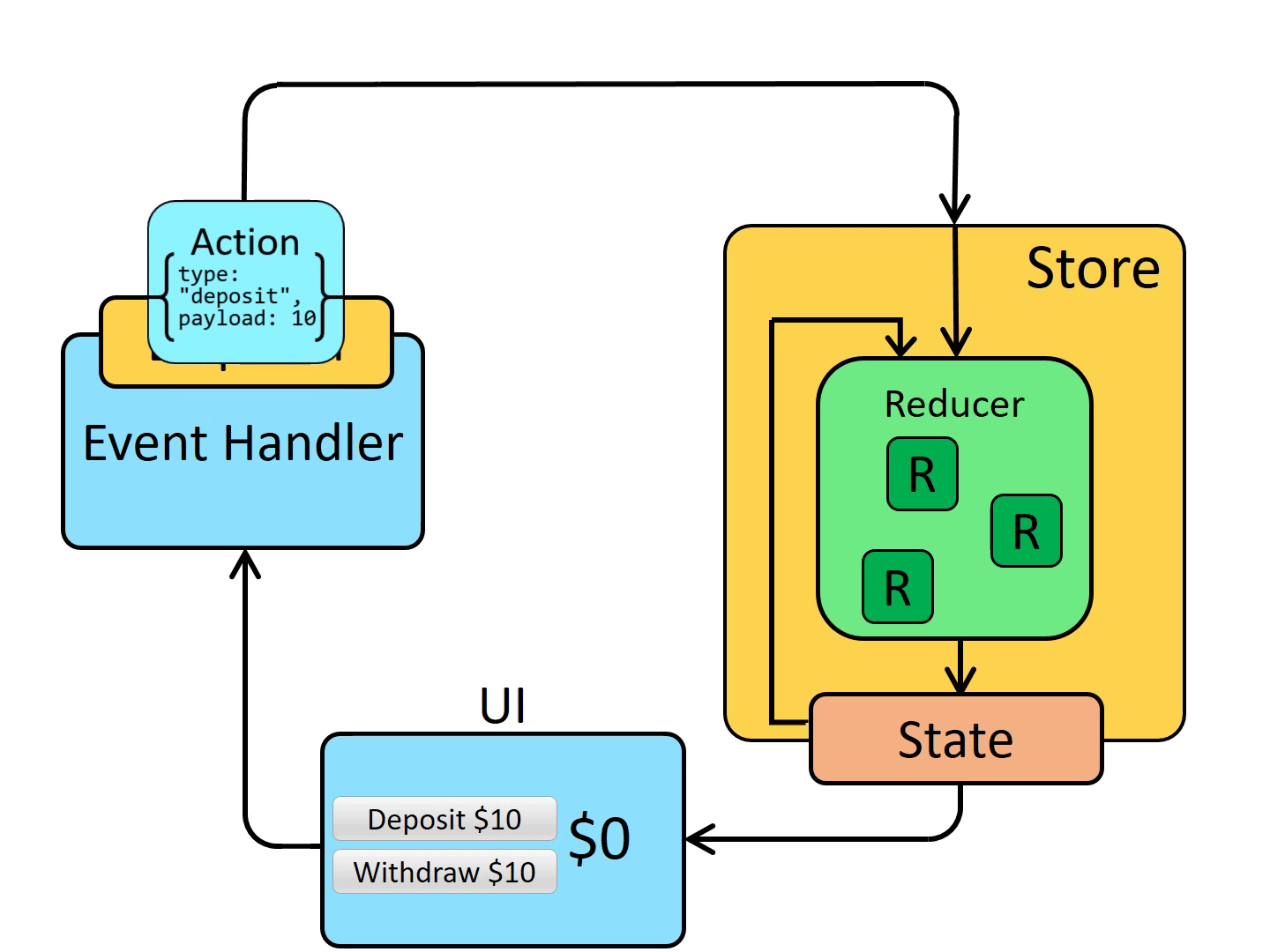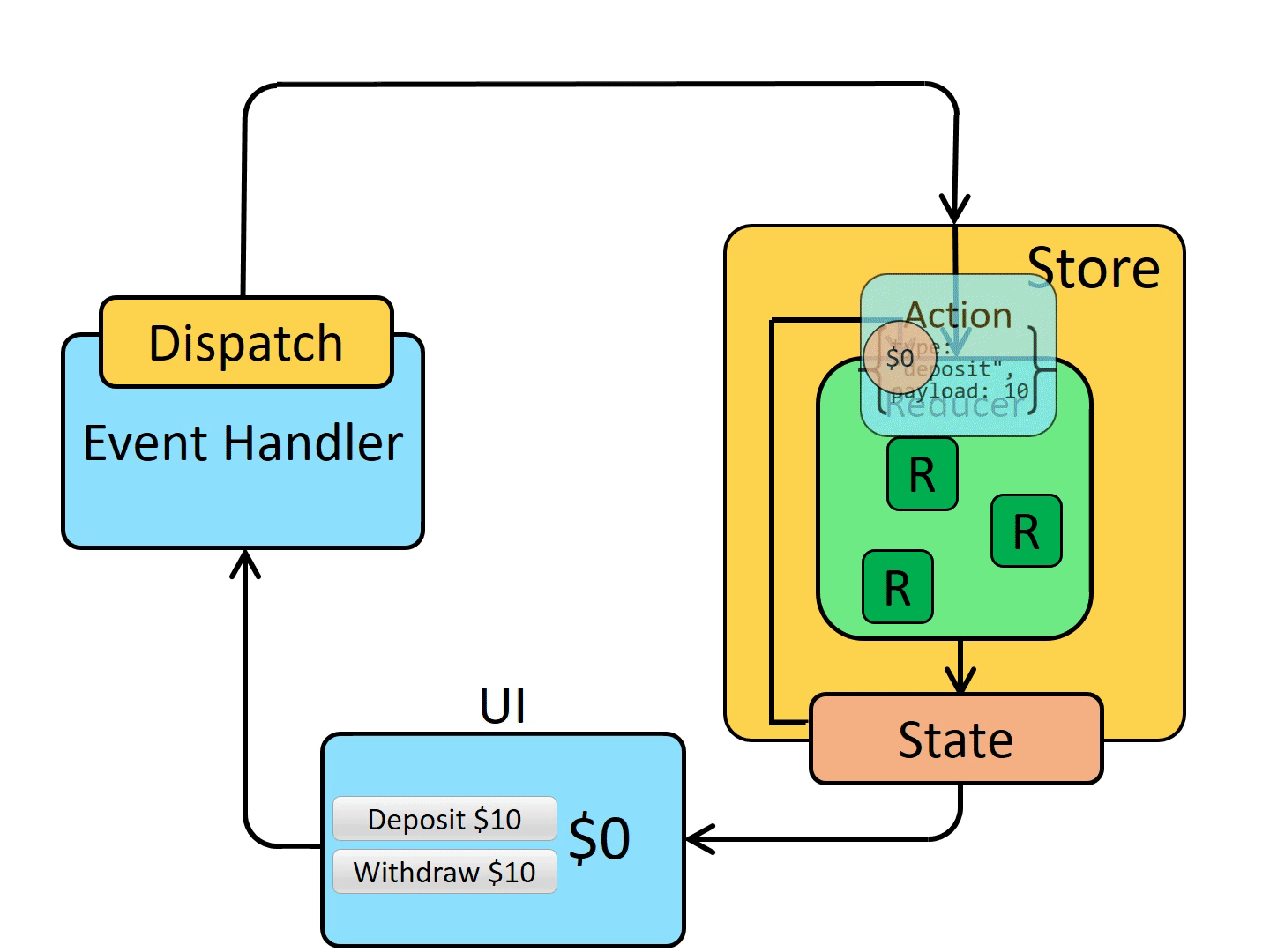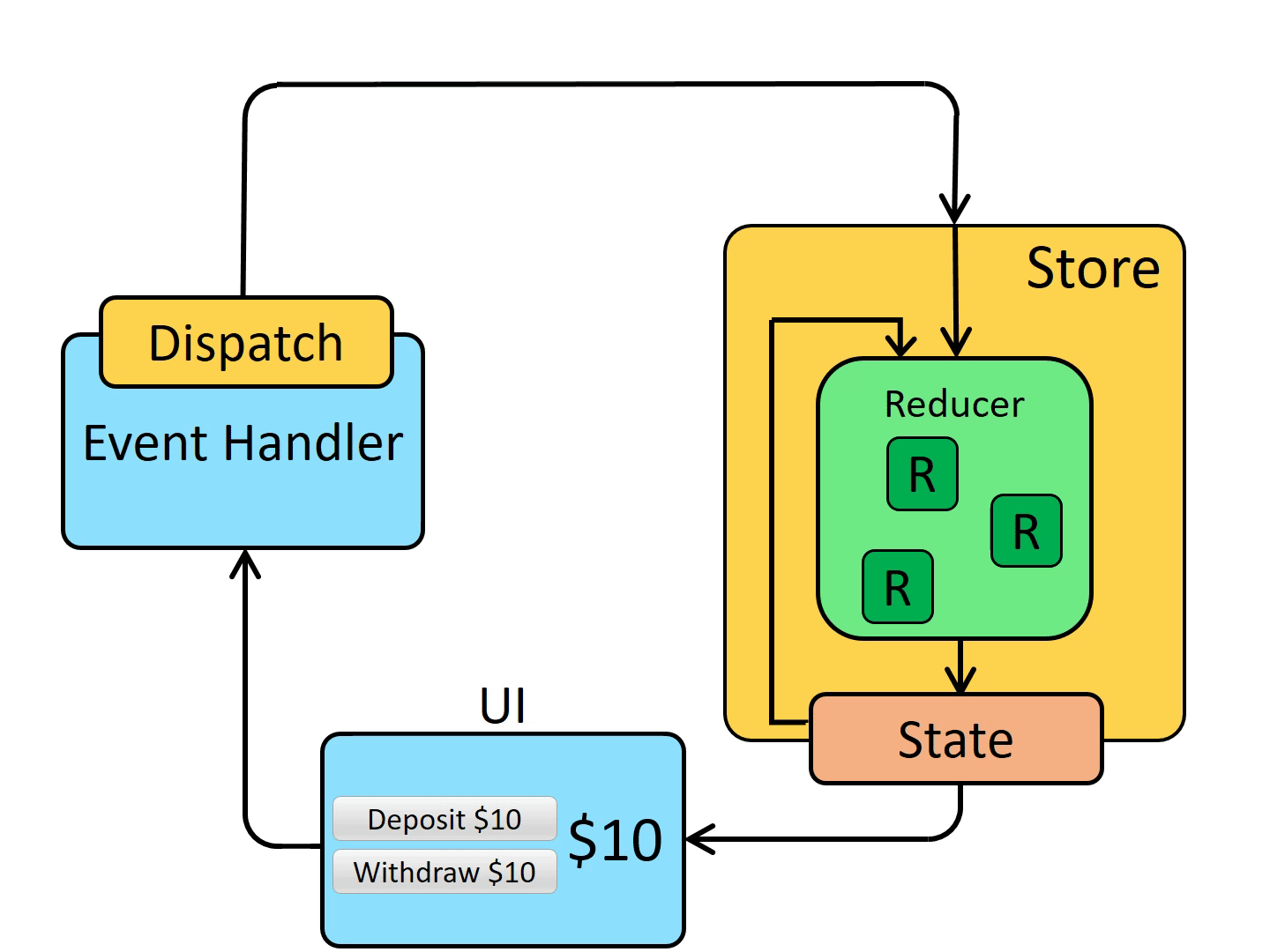
Redux - Store
Redux는 Flux 패턴과는 다르게 단일 store를 사용하며 공식 문서에 따르면 아래와 같은 장점을 제공한다.
애플리케이션의 모든 상태는 하나의 store 안에 하나의 객체 트리 구조로 저장된다. 하나의 트리 상태를 사용하면, 애플리케이션을
디버깅하거나 검사하기 쉽다.
또한 전통적으로 구현하기 어려웠던 일부기능, 예를 들어 Undo/Redo 등도 모든 상태가 단일 트리에 저장되어 있으면 굉장히 구현하기 쉽다.
만약 Redux가 다중 store였다면 하나의 store 업데이트를 위해 다른 store의 업데이트를 기다려야 했을 것이다. 또한 여러 상태가 분리되어 있기에 상태 간의 관계를 관리 및 추적하는 것이 어려웠을 것이다.
undo/redo의 경우, 상태 업데이트시 모든 관련 store를 복제해 과거 상태를 추적해야 하기에 MVC 프레임워크를 이용해 구현하는 것이 쉬운 작업은 아니다.
console.log(store.getState())
/* Prints
{
visibilityFilter: 'SHOW_ALL',
todos: [
{
text: 'Consider using Redux',
completed: true,
},
{
text: 'Keep all state in a single tree',
completed: false
}
]
}
*/[참고 자료]
https://redux.js.org/usage/implementing-undo-history
Redux - Action
상태는 무조건 읽기 전용으로 상태를 변경하는 유일한 방법은 어떤 일이 일어나는지 나타내는 action 객체를 전달하는 것뿐이다.
이를 통해 View나 네트워크 콜백 모두 직접적으로 상태를 변경하지 못한다는 것을 보장할 수 있다. 모든 상태는 중앙에서 관리되기에, 엄격한 순서에 따라 하나씩 실행되기에 조심해야 할 race condition이 없다. 작업은 단순한 객체일 뿐이므로, 디버깅이나 테스트 목적으로 녹화, 직렬화, 저장 및 재생할 수 있다.
store.dispatch({
type: 'COMPLETE_TODO',
index: 1,
})
store.dispatch({
type: 'SET_VISIBILITY_FILTER',
filter: 'SHOW_COMPLETED',
})이때 type이 string 형태인 이유는 직렬화가 가능하기에 시간별 디버깅, 액션 기록 및 리플레이 같은 Redux의 여러가지 기능을 활성화하기 때문이다. 그렇기에 직렬화가 가능하며 쉽게 표현할 수 있는 string 형태로 사용하지만 액션이 미들웨어에서 사용되도록 의도된 경우 Symbol, Promises 같은 직렬 불가능한 값을 사용해도 된다.
[참고 자료]
https://redux.js.org/faq/actions#why-should-type-be-a-string-why-should-my-action-types-be-constants
Redux - Reducer
Action을 통해서 상태트리가 어떻게 바뀌는지 묘사하기 위해서는, 순수 Reducer를 작성해야 한다.
Reducer는 이전의 상태값과 액션을 받아 다음 상태를 반환하는 순수 함수다. 여기서 이전 상태값이 아닌 새로운 상태 객체를 반환해야 한다. 단일 Reducer로 시작할 수 있으며, 앱이 커지면 상태트리의 일부를 관리하는 작은 Reducers로 구성할 수 있다. Reducer는 단순 함수이기에 순서를 정하거나, 추가 데이터를 넘기거나, 페이징 같은 기능을 위한 재사용 Reducer를 만들 수 있다.
function visibilityFilter(state = 'SHOW_ALL', action) {
switch (action.type) {
case 'SET_VISIBILITY_FILTER':
return action.filter
default:
return state
}
}
function todos(state = [], action) {
switch (action.type) {
case 'ADD_TODO':
return [
...state,
{
text: action.text,
completed: false,
},
]
case 'COMPLETE_TODO':
return state.map((todo, index) => {
if (index === action.index) {
return Object.assign({}, todo, {
completed: true,
})
}
return todo
})
default:
return state
}
}
import { combineReducers, createStore } from 'redux'
const reducer = combineReducers({ visibilityFilter, todos })
const store = createStore(reducer)아래는 redux 내부 코드로 redux는 주어진 상태(객체)를 가져와 루프에서 각 reducer에 전달한다. 그리고 변경사항이 있으면 reducer가 새 객체를, 변경사항이 없다면 이전 객체를 다시 받을 것을 기대한다. redux는 단순히 두 객체의 메모리 위치를 비교하는 얕은 비교를 통해 이전 객체와 새 객체가 같은지 확인하기에 만약 reducer에서 새로운 객체가 아닌 이전 객체의 property만 변경해 반환한다면 store는 업데이트되지 않을 것이다. 따라서 reducer는 새로운 상태 객체를 반환하는 순수 함수여야 한다.
let hasChanged = false
const nextState = {}
for (let i = 0; i < finalReducerKeys.length; i++) {
const key = finalReducerKeys[i]
const reducer = finalReducers[key]
const previousStateForKey = state[key]
const nextStateForKey = reducer(previousStateForKey, action)
if (typeof nextStateForKey === 'undefined') {
const errorMessage = getUndefinedStateErrorMessage(key, action)
throw new Error(errorMessage)
}
nextState[key] = nextStateForKey
hasChanged = hasChanged || nextStateForKey !== previousStateForKey
}
hasChanged =
hasChanged || finalReducerKeys.length !== Object.keys(state).length
return hasChanged ? nextState : state공부를 하면서 reducer는 왜 순수함수로 설계된 건지 궁금했다. 만약 store의 비교 방식이 얕은 복사가 아니라 깊은 복사라면 어땠을까? 상태 객체가 커지고 중첩 property가 많아질수록 비교해야 하는 횟수도 많기 때문에 비용이 많이 들 것이다. 따라서 redux는 얕은 비교로 상태 변화를 확인하기에 개발자로 하여금 reducer에서 새로운 객체를 반환하도록 한 것이 아닐까 싶다.
[참고 자료]
https://www.freecodecamp.org/news/why-redux-needs-reducers-to-be-pure-functions-d438c58ae468/
상태 변경시 subscribe는 어떻게 실행되는 걸까?
subscribe와 dispatch는 pub/sub 패턴을 기반으로 구현되어 있으며 createStore 함수 내부를 간단히 표현한 코드를 살펴본다.
- subscribe는 콜백 함수를 listeners 배열에 저장한다.
- dispatch가 호출되면 reducer를 통해 새로운 상태를 계산한다.
- 계산된 새로운 상태를 store에 저장한다.
- 저장 후 listeners.forEach(listener => listener())를 호출해 모든 콜백 함수를 실행한다.
function createStore(reducer) {
let state; // 현재 상태
let listeners = []; // 콜백 함수 배열
function getState() {
return state;
}
function subscribe(listener) {
listeners.push(listener);
return function unsubscribe() {
listeners = listeners.filter(l => l !== listener);
};
}
function dispatch(action) {
state = reducer(state, action); // 상태를 reducer를 통해 갱신
listeners.forEach(listener => listener()); // 콜백 함수 호출
}
// 초기 상태 설정
dispatch({ type: '@@redux/INIT' });
return { getState, subscribe, dispatch };
}Redux와 Redux Toolkit의 다른 점
Redux의 핵심과 동작원리에 대해 알아봤으니 본격적으로 Redux Toolkit에 대해 파헤쳐본다. Redux Toolkit은 Redux 로직에서 보일러 플레이트 코드를 제거하고, Redux를 간단하게 사용할 수 있는 API를 제공하는 라이브러리로 Redux 공식 문서에서도 Redux Toolkit(RTK) 사용을 권장한다. 그러면 Redux Toolkit은 어떻게 동작하는지 알아보자.
configureStore
Redux store 설정 함수로 reducer를 결합해부며 이름이 있는 옵션 매개변수를 사용하기에 createStore보다 구성이 쉽다.
import { configureStore } from '@reduxjs/toolkit'
import todosReducer from '../features/todos/todosSlice'
import filtersReducer from '../features/filters/filtersSlice'
export const store = configureStore({
reducer: {
todos: todosReducer,
filters: filtersReducer
}
})createSlice
Immer 라이브러리를 사용하는 reducer를 추가할 수 있다. redux의 reducer에서는 매번 새로운 객체를 반환해야 했지만 Immer 덕분에 spreads 문법 없이도 state.value = 123 와 같은 mutating(변이) 구문을 통해 불변성을 유지하며 상태를 업데이트할 수 있다. 또한 각 reducer에 대한 액션 생성자 함수를 자동으로 생성한다.
import { createSlice } from '@reduxjs/toolkit'
const todosSlice = createSlice({
name: 'todos',
initialState: [],
reducers: {
todoAdded(state, action) {
state.push({
id: action.payload.id,
text: action.payload.text,
completed: false
})
},
todoToggled(state, action) {
const todo = state.find(todo => todo.id === action.payload)
todo.completed = !todo.completed
}
}
})
export const { todoAdded, todoToggled } = todosSlice.actions
export default todosSlice.reducerRedux Toolkit과 Immer
Redux의 기본 규칙은 reducer가 기존 상태를 변경할 수 없으며 새로운 상태를 반환하는 순수 함수여야 한다. 그런데 만약 상태가 중첩 객체이며 매우 깊은 depth level이라면 아래와 같은 식으로 모든 depth의 property를 복사해 반환해야 할 것이며 이는 매우 수고로운 일이다.
function handwrittenReducer(state, action) {
return {
...state,
first: {
...state.first,
second: {
...state.first.second,
[action.someId]: {
...state.first.second[action.someId],
fourth: action.someValue,
},
},
},
}
}Redux Toolkit에서는 createReducer 내부에서 Immer 라이브러리를 사용하고 있기에 상태를 변이하는 구문을 사용하면서 불변성을 유지할 수 있다. 따라서 새로운 객체를 반환할 필요가 없다. 또한 createSlice는 내부적으로 createReducer를 사용하기에 안전하게 상태를 변이할 수 있다.
const todosReducer = createReducer([], (builder) => {
builder.addCase('todos/todoAdded', (state, action) => {
// "mutate" the array by calling push()
state.push(action.payload)
})
})
const todosSlice = createSlice({
name: 'todos',
initialState: [],
reducers: {
todoAdded(state, action) {
state.push(action.payload)
},
},
})그런데 Immer는 어떤 원리를 사용했길래 불변성을 유지해주는 것일까?
Immer의 핵심 원리는 Copy-on-write(이하 기록 중 복사)와 Proxy(이하 프록시)에 있다. 기록 중 복사란 자원을 공유하다가도 수정해야 할 경우가 발생하면 자원의 복사본을 쓰게 하는 개념이다. immer는 프록시 객체를 이용해서 원본 객체인 상태 객체 대신 프록시 객체를 대신 조작(변경) 하는 것이다.
Immer를 사용하면 상태 객체에서 실제로 변경할 부분만 골라서 변경이 되고, 다른 부분은 기존 상태 객체와 동일한 것을 확인할 수 있다.
아래 코드를 보면 실제로 변경을 가한 a2 프로퍼티 객체만 변경된 것을 확인할 수 있으며 해당 프로퍼티를 트리노드로 봤을 떄의 상위 노드인 obj 또한 참조가 변경되어 newObj와 다른 것을 확인할 수 있다.
import { produce } from 'immer';
const obj = { a1: { b1: 1 }, a2: { b2: 2 }, a3: { b3: 3 } };
const newObj = produce(obj, (draft) => {
draft.a2.b2 = 4;
});
console.log(obj === newObj); // false
console.log(obj.a1 === newObj.a1); // true
console.log(obj.a2 === newObj.a2); // false
console.log(obj.a3 === newObj.a3); // true결론적으로 Redux Toolkit은 Immer를 사용해 deep copy를 구현하지 않아도 되는 편리함을 제공할 뿐만 아니라 deep copy를 통해서 객체의 속성을 새로 생성하는 것이 아닌 변경된 값에 한해서만 참조 메모리 주소만 변경하기에 메모리 공간 사용 측면에서도 장점을 가지고 있다.
결론적으로 Redux Toolkit은 데이터가 집중화(Centralized) 되어 있어서 예측 가능하며(Predictable) 데이터 흐름이 단방향이라서 디버깅하기 쉽다는 (Debuggable) Redux의 장점을 가지고 있다. 또한 Redux와 연관된 좋은 생태계가 구축되어 있어서 필요에 맞게 유연하게(Flexible) 구현할 수 있다
[참고 자료]
https://redux-toolkit.js.org/usage/immer-reducers#immutability-and-redux
https://ui.toast.com/posts/ko_20220217
Redux Toolkit 장단점
위에서도 살펴봤듯이 Redux Toolkit은 전역 state 관리, 단방향 데이터 흐름으로 인한 쉬운 상태 관리 추적, 복잡한 상태의 변이 구문 사용을 통한 상태 업데이트 및 불변성 유지와 같은 장점을 제공한다.
그러나 다른 라이브러리들에 비해 코드량이 상대적으로 많고 패키지 용량(5.6MB)이 크다. 또한 러닝커브가 상대적으로 높다.
Redux Toolkit 외의 다른 상태 관리 라이브러리
Redux Toolkit 외 다른 상태 관리 라이브러리들도 존재한다.
- 훅을 기반으로 가능한 작은 상태를 효율적으로 관리하는 recoil, jotai
- redux와 비슷하게 큰 스토어를 기반으로 상태 관리하는 zustand
zustand
간소화된 flux 패턴을 사용하는 경량화된 상태 관리 라이브러리다.
아래는 zustand의 간단한 사용법으로 먼저 store를 만들고 컴포넌트와 바인딩하면 끝이다. zustand는 store 생성 함수 호출시 Context가 아닌 store의 클로저를 사용하기에 Context의 변화를 알리는 Provider 구성도 필요 없다.
zustand는 Top-Down 방식으로 전역 상태를 접근하기 때문에, 전체적인 오버뷰에서 디테일 세부사항으로 스토어 모델링을 하는 것이 좋다. 예를 들어, 블로그를 위한 스토어를 만든다고 하면 블로그 > 포스트 > 작가, 제목, 내용 이런 식으로 접근할 수 있다.
import { create } from 'zustand'
const useStore = create((set) => ({
bears: 0,
increasePopulation: () => set((state) => ({ bears: state.bears + 1 })),
removeAllBears: () => set({ bears: 0 }),
updateBears: (newBears) => set({ bears: newBears }),
}))
function BearCounter() {
const bears = useStore((state) => state.bears)
return <h1>{bears} around here...</h1>
}
function Controls() {
const increasePopulation = useStore((state) => state.increasePopulation)
return <button onClick={increasePopulation}>one up</button>
}장점
- 라이브러리 크기가 1kB로 가볍다.
- redux toolkit에 비해 보일러 플레이트 코드 없이 상태를 직관적으로 표현한다.
- SSR 지원 (Redux Toolkit도 next-redux-wrapper를 사용하면 지원하지만 2022년이 마지막 업데이트라 현재는 관리되지 않는 것 같다.)
- 낮은 러닝 커브
단점
- Redux Toolkit보다는 보조 라이브러리나 미들웨어가 부족한 편이기에 직접 구현하거나 다른 수단이 필요할 것 같다.
recoil
기존에 Redux 등 전역 상태 관리 도구는 리액트 라이브러리가 아니라, 리액트 내부 스케줄러에 접근할 수 없었다. 그래서 동시성 모드의 사용이 어려워지는 문제를 해결하기 위해 recoil이 만들어졌다.
Recoil은 atoms(아톰)이라는 상태 단위를 사용하는데, 업데이트와 구독이 가능하다. atom이 업데이트됐을 때 해당 atom을 구독하는 컴포넌트들은 리렌더링이 일어나게 된다. 모든 atom은 전역적으로 고유의 키값을 가져야 하고, 이 키값으로 컴포넌트에서 useRecoilState로 불러올 수 있다.
const fontSizeState = atom({
key: 'fontSizeState',
default: 14
});
const fontSizeLabelState = selector({
key: 'fontSizeLabelState',
get: ({get}) => {
const fontSize = get(fontSizeState);
const unit = 'px';
return `${fontSize}${unit}`;
}
});
function FontButton() {
const [fontSize, setFontSize] = useRecoilState(fontSizeState);
const fontSizeLabel = useRecoilValue(fontSizeLabelState);
return (
<>
<div>Current font size: ${fontSizeLabel}</div>
<button onClick={setFontSize(fontSize + 1)} style={{fontSize}}>
Click to Change
</button>
</>
)
};장점
- React 문법 친화적으로 React 상태처럼 간단한 get/set 인터페이스로 사용할 수 있는 보일러 플레이트가 없는 API 제공
- 비동기 처리를 추가적인 라이브러리 없이 (redux-thunk, redux-saga) recoil 안에서 가능
- 내부적으로 캐싱을 지원하며 동일한 atom 값에 대해 내부적으로 메모이제이션된 값을 반환해 속도가 빠름
단점
- 역사가 오래되지 않아 참고 자료가 부족하며 현재는 주기적인 업데이트가 되지 않고 있음 (2014.12 기준으로 업데이트된지 2년이 넘었다.)
- 전역 상태를 아톰으로 관리하고 어느 컴포넌트에서도 바로 아톰을 구독해서 업데이트를 받다 보니, atom과 selector가 많아지면 의존성이 여러 방향으로 엮이면서 상태 변화 예측이 어려워진다. (flux의 다중 store로 인한 이슈와 비슷한 것 같다..)
jotai
아토믹 접근을 가지고 만든 리액트 상태 관리 도구로 recoil과 비슷한 면이 있다.
그러나 recoil과 다른 점은 atom 작성시 고유의 키값이 필요하지 않고 Provider 또한 필요하지 않다. (여러 Provider 정의도 가능하다)
import { atom, useAtom } from 'jotai'
const animeAtom = atom([
{
title: 'Ghost in the Shell',
year: 1995,
watched: true
},
{
title: 'Serial Experiments Lain',
year: 1998,
watched: false
}
])
const AnimeApp = () => {
const [anime, setAnime] = useAtom(animeAtom)
return (
<>
<ul>
{anime.map((item) => (
<li key={item.title}>{item.title}</li>
))}
</ul>
<button onClick={() => {
setAnime((anime) => [
...anime,
{
title: 'Cowboy Bebop',
year: 1998,
watched: false
}
])
}}>
Add Cowboy Bebop
</button>
<>
)
}장점
- 리렌더링을 줄여주는 selectAtom이나 splitAtom과 같은 유틸에 대한 지원
- SSR을 지원하는 useHydrateAtoms 같은 유틸 존재
단점
- 다른 상태관리 라이브러리에 비해 사용자 수가 많지 않아 생태계가 넓지 않다
- 레퍼런스가 부족하다.
그러면 어떤 때에 어떤 라이브러리를 사용해야 할까?
일단 Top-Down 방식의 Flux 패턴을 사용하고 싶다면? → Redux-Toolkit 혹은 Zustand
Bottom-Up 방식의 atomic 패턴을 사용하고 싶다면 ? → jotai (recoil은 현재 관리되지 않기에 위험부담이 있을 수 있다고 생각된다.)
개인적으로는 Top-Down 방식을 선호해 Redux-Toolkit 라이브러리를 사용했었다. 서비스가 커질수록 독립적인 store에서 연관 관계가 많고 서로 의존하는 store를 관리하게 되는 것 같다. (user, user_role, user_auth 등..)
이때 Bottom-Up 방식으로 store를 잘 설계하면 문제가 없지만 store 업데이트 순서가 보장되지 않으면 디버깅이 어렵고 상태 변화 에측이 힘들어진다. 따라서 아주 작은 프로젝트가 아니라면 Top-Down 방식을 사용하는 게 좋다고 생각된다.
그래서 통계분석 대시보드를 개발할 때도 Dashboard > Card & Datasource 등 데이터 간의 연관관계가 많고 의존성이 커서 Recoil에서 Redux Toolkit로 전환했었다.
요약
- 기존 MVC 패턴는 양방향 데이터 바인딩으로 변경 시나리오가 복잡해져 상태 변화를 추적 및 관리하기가 어려웠다. 따라서 단방향 데이터 바인딩의 Flux 패턴의 라이브러리가 만들어졌다.
- Redux는 Flux 패턴의 단방향 데이터 바인딩과 Elm 아키텍처의 단일 저장소 특징을 가지고 있다. 따라서 양방향 데이터 바인딩이나 다중 저장소 관리 방식보다 상태 변화를 추적(디버깅)하기 쉽다.
- Redux는 단방향 데이터 흐름 방식이기에 사용자 액션에 따라 데이터 갱신 및 업데이트 방식에 대한 코드량이 많다. 또한 reducer 순수함수를 사용했기에 중첩 객체일 경우 매번 새로운 객체를 반환하는 코드를 추가해야 하는 수고로움이 존재했다.
- Redux Toolkit은 immer 라이브러리를 이용하기에
state.value = 123와 같은 mutation(변이) 구문을 통해 불변성을 유지하며 상태를 업데이트할 수 있다. (또한 변경된 값에 한해서만 참조 메모리 주소가 변경되기에 메모리 공간 사용 측면에서도 큰 장점이다.) - 대규모 서비스라면 연관 관계가 많고 서로 의존적인 상태(user, user_role, user_auth)가 많아지기에 하나의 저장소를 쪼개서 사용하는 Top-Down 방식의 상태 관리 라이브러리인 Zustand, Redux-Toolkit를 사용하는 것이 좋을 것 같다.
- 서비스 규모가 크지 않다면 독립적인 상태가 주를 이루기에 작은 상태를 결합해서 사용하는 Bottom-Up 방식의 jotai를 사용하는 것이 좋을 것 같다.
'React' 카테고리의 다른 글
| [React Query] React Query를 왜 사용할까? (1) | 2025.03.09 |
|---|---|
| [React] React 성능 개선의 여정 (144ms에서 61ms까지) (1) | 2024.11.24 |
| [React] React Hook 파헤쳐보기 - useCallback, useMemo (React.memo를 곁들인) (2) | 2024.11.16 |
| [React] React Hook 파헤쳐보기 - useEffect (2) | 2024.11.08 |
| React 동작원리(Virtual DOM과 Fiber) (1) | 2024.11.03 |



